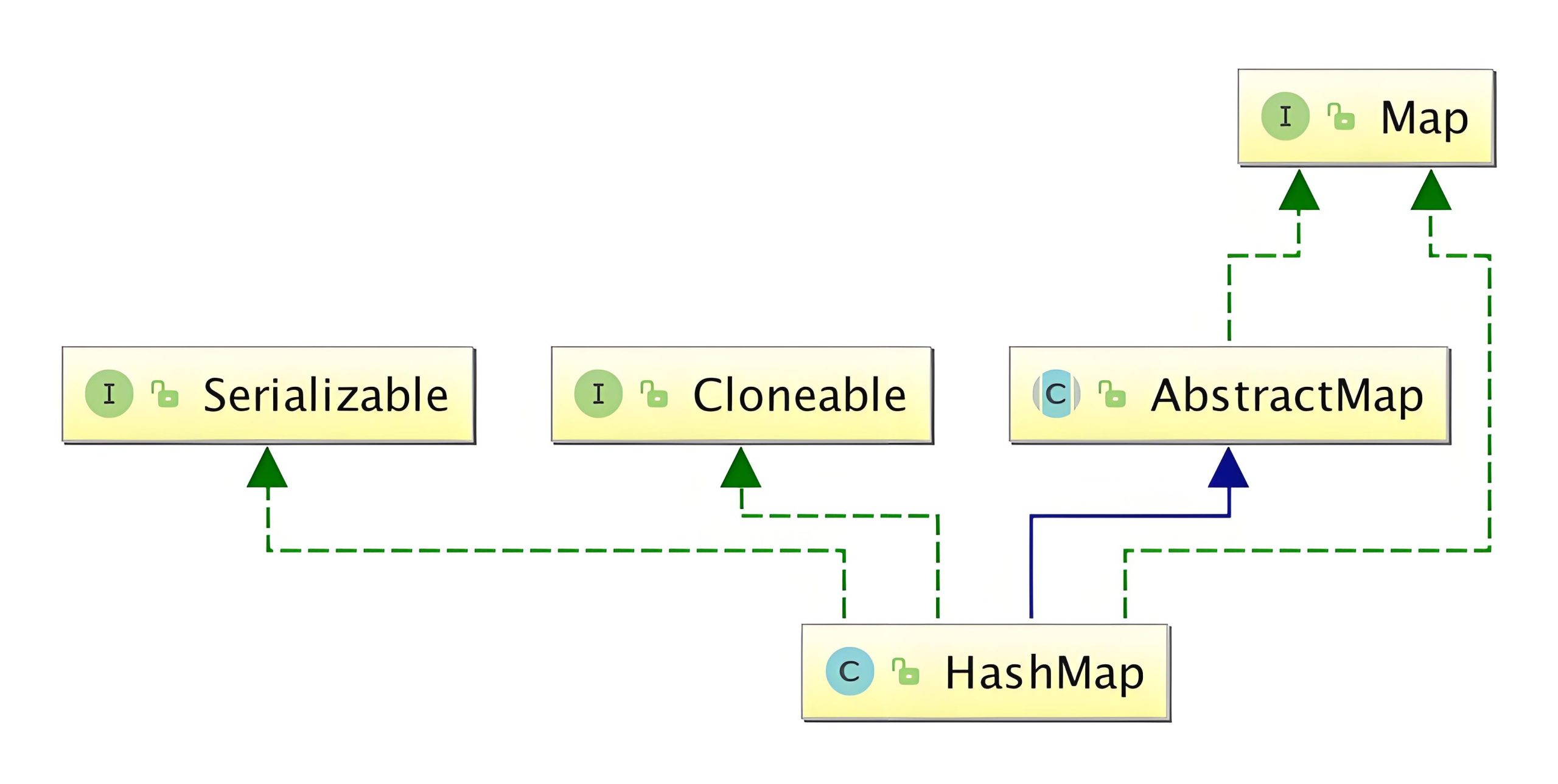
1.Overview of the Map Interface
Map is one of the core interfaces in the Java Collections Framework, used for storing key-value pairs. Unlike List and Set, Map is not a subinterface of the Collection interface but an independent top-level interface. Each key in a Map is unique, but values can be duplicated.
Basic Characteristics of Map
- Keys must be unique, while values can be duplicated
- One key can only map to one value
- Different keys can map to the same value
- Both keys and values can be null (depending on the specific implementation)
2.Core Methods of the Map Interface
Basic Operation Methods
// Add a key-value pair
V put(K key, V value)
// Get the value for a specified key
V get(Object key)
// Remove the key-value pair for a specified key
V remove(Object key)
// Check if a specified key is contained
boolean containsKey(Object key)
// Check if a specified value is contained
boolean containsValue(Object value)
// Get the size of the Map
int size()
// Check if the Map is empty
boolean isEmpty()
// Clear the Map
void clear()Bulk Operation Methods
// Add all key-value pairs from another Map to the current Map
void putAll(Map<? extends K, ? extends V> m)
// Get a set of all keys
Set<K> keySet()
// Get a collection of all values
Collection<V> values()
// Get a set of all key-value pairs
Set<Map.Entry<K, V>> entrySet()3.Detailed Explanation of Main Implementation Classes
3.1 HashMap
HashMap is the most commonly used implementation class of the Map interface, based on a hash table.
Features:
- Allows null keys and null values
- Not thread-safe
- Stores elements in an unordered manner
- Average time complexity: O(1)
Internal Structure:
- Before JDK 1.8: Array + Linked List
- JDK 1.8 and later: Array + Linked List + Red-Black Tree
// HashMap example
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("apple", 10);
hashMap.put("banana", 20);
hashMap.put("orange", 15);
// Traverse HashMap
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}3.2 LinkedHashMap
LinkedHashMap inherits from HashMap and maintains insertion order or access order.
Features:
- Maintains insertion order or access order
- Implemented based on hash table and doubly linked list
- Slightly lower performance than HashMap
// LinkedHashMap example
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("first", 1);
linkedHashMap.put("second", 2);
linkedHashMap.put("third", 3);
// Output order is consistent with insertion order
linkedHashMap.forEach((k, v) -> System.out.println(k + ": " + v));3.3 TreeMap
TreeMap is implemented based on a red-black tree and is an ordered Map.
Features:
- Sorts according to the natural order of keys or a custom Comparator
- Does not allow null keys, but allows null values
- Time complexity: O(log n)
// TreeMap example
Map<String, Integer> treeMap = new TreeMap<>();
treeMap.put("zebra", 26);
treeMap.put("apple", 1);
treeMap.put("banana", 2);
// Output in lexicographical order of keys
treeMap.forEach((k, v) -> System.out.println(k + ": " + v));
// Output: apple: 1, banana: 2, zebra: 263.4 ConcurrentHashMap
ConcurrentHashMap is a thread-safe implementation of HashMap.
Features:
- Thread-safe
- High concurrency performance
- Does not allow null keys and null values
- Uses segment lock mechanism (changed to CAS + synchronized in JDK 1.8)
// ConcurrentHashMap example
Map<String, Integer> concurrentMap = new ConcurrentHashMap<>();
concurrentMap.put("thread1", 1);
concurrentMap.put("thread2", 2);
// Atomic operations
concurrentMap.putIfAbsent("thread3", 3);
concurrentMap.computeIfAbsent("thread4", k -> 4);4.Advanced Features and Methods
4.1 Methods Added in JDK 1.8
Map<String, Integer> map = new HashMap<>();
map.put("a", 1);
map.put("b", 2);
// getOrDefault - Get the value, return default if not present
Integer value = map.getOrDefault("c", 0); // Returns 0
// putIfAbsent - Add if the key does not exist
map.putIfAbsent("c", 3);
// replace - Replace the value of the specified key
map.replace("a", 10);
// compute - Calculate a new value
map.compute("a", (k, v) -> v * 2); // The value of a becomes 20
// merge - Merge values
map.merge("d", 1, (oldVal, newVal) -> oldVal + newVal);
4.2 Using with Stream API
Map<String, Integer> map = new HashMap<>();
map.put("apple", 10);
map.put("banana", 20);
map.put("orange", 15);
// Filter and collect to a new Map
Map<String, Integer> filtered = map.entrySet().stream()
.filter(entry -> entry.getValue() > 10)
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue
));
// Transform values
Map<String, String> transformed = map.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> "Count: " + entry.getValue()
));
5.Performance Comparison and Selection Recommendations
Performance Comparison Table
| Implementation Class | Lookup | Insertion | Deletion | Ordering | Thread Safety |
|---|---|---|---|---|---|
| HashMap | O(1) | O(1) | O(1) | None | No |
| LinkedHashMap | O(1) | O(1) | O(1) | Insertion order | No |
| TreeMap | O(log n) | O(log n) | O(log n) | Key-sorted | No |
| ConcurrentHashMap | O(1) | O(1) | O(1) | None | Yes |
Selection Recommendations
Use HashMap when:
- You need the fastest lookup, insertion, and deletion operations
- You don’t need to maintain order
- Working in a single-threaded environment
Use LinkedHashMap when:
- You need to maintain insertion order or access order
- You need to implement an LRU cache
Use TreeMap when:
- You need sorting by keys
- You need range query functionality
Use ConcurrentHashMap when:
- Working in a multi-threaded environment
- You need high concurrency performance
6.Best Practices and Considerations
6.1 Correctly Overriding hashCode() and equals()
public class Person {
private String name;
private int age;
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}6.2 Setting Initial Capacity
// Setting initial capacity can improve performance if the Map size is known
Map<String, Integer> map = new HashMap<>(16);
// For data with known size, calculate an appropriate initial capacity
int expectedSize = 100;
int initialCapacity = (int) (expectedSize / 0.75) + 1;
Map<String, Integer> optimizedMap = new HashMap<>(initialCapacity);6.3 Avoiding Concurrent Modification Exceptions
Map<String, Integer> map = new HashMap<>();
map.put("a", 1);
map.put("b", 2);
// Incorrect approach - will throw ConcurrentModificationException
// for (String key : map.keySet()) {
// if (key.equals("a")) {
// map.remove(key);
// }
// }
// Correct approach - using Iterator
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
if (entry.getKey().equals("a")) {
iterator.remove();
}
}
6.4 Using Immutable Maps
// Create an immutable Map
Map<String, Integer> immutableMap = Map.of(
"apple", 10,
"banana", 20,
"orange", 15
);
// Or use Collections.unmodifiableMap()
Map<String, Integer> originalMap = new HashMap<>();
originalMap.put("a", 1);
Map<String, Integer> unmodifiableMap = Collections.unmodifiableMap(originalMap);
7.Practical Application Scenarios
7.1 Cache Implementation
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int maxSize;
public LRUCache(int maxSize) {
super(16, 0.75f, true); // accessOrder = true
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
}7.2 Word Frequency Counting
public Map<String, Integer> countWords(String text) {
Map<String, Integer> wordCount = new HashMap<>();
String[] words = text.toLowerCase().split("\\s+");
for (String word : words) {
wordCount.merge(word, 1, Integer::sum);
}
return wordCount;
}7.3 Grouping Operations
// Group students by grade
List<Student> students = getStudents();
Map<String, List<Student>> studentsByGrade = students.stream()
.collect(Collectors.groupingBy(Student::getGrade));