1. Overview of Thread Pools
(1) What is a Thread Pool
A thread pool, simply put, is a mechanism that pre-creates a number of threads and uniformly manages and reuses them. In traditional multi-threaded programming, if a new thread is created every time a task needs to be executed and destroyed after the task is completed, frequent thread creation and destruction consume a lot of system resources (such as CPU time and memory). This overhead becomes particularly significant in high-concurrency scenarios with a large number of short tasks. A thread pool, however, prepares a set of threads in advance, assigns tasks to these threads for execution, and after the task is completed, the thread is not destroyed but returns to the pool to wait for the next task assignment. This effectively reduces resource waste and improves system efficiency and response speed.
(2) Advantages of Thread Pools
- Reduced resource consumption: As mentioned earlier, it avoids the resource overhead caused by frequent thread creation and destruction, allowing more rational use of resources such as CPU and memory.
- Faster response speed: Since there are already available threads in the thread pool, when a new task arrives, it can be immediately assigned to a thread for execution without waiting for thread creation, thus responding to user requests or processing business logic faster and improving system response performance.
- Easier thread management: It enables unified management and monitoring of the number and status of threads in the thread pool. For example, parameters such as the maximum number of threads and core threads can be set, and thread reuse can be easily implemented. This ensures the system runs stably within a reasonable range of thread resource usage, avoiding issues like system resource exhaustion or performance degradation caused by too many threads.
2. Core Components and Principles of Thread Pools
(1) Core Pool Size
The core pool size is the number of threads that remain alive in the thread pool at all times, even when they are idle. These core threads continuously wait for tasks. Once a task is submitted to the thread pool, it is executed by these core threads, forming the basic force for task execution in the thread pool and ensuring that there are always available threads to respond to task requests promptly.
(2) Maximum Pool Size
The maximum pool size specifies the upper limit of the number of threads that the thread pool can hold. When the number of tasks increases, core threads are all busy, and the task queue is full. If new tasks continue to be submitted, the thread pool will create new threads to process the tasks as needed, but the total number of threads will not exceed the maximum pool size. Once the number of threads reaches this limit, subsequent new tasks will wait for execution according to the thread pool’s task queue mechanism.
(3) Blocking Queue
A blocking queue is a queue used to store tasks waiting for execution. When threads in the thread pool cannot immediately process newly submitted tasks (e.g., all core threads are busy), these tasks are added to the blocking queue to wait in line. There are multiple implementations of blocking queues, such as ArrayBlockingQueue (an array-based bounded blocking queue that requires a fixed capacity), LinkedBlockingQueue (a linked-list-based blocking queue that can be bounded by specifying a capacity, defaulting to unbounded), and SynchronousQueue (a blocking queue that does not store elements; each insertion operation must wait for a corresponding removal operation, often used in transitive scenarios). The characteristics of different blocking queues affect the behavior and performance of the thread pool, so they should be selected based on actual business scenarios.
(4) Thread Factory
A thread factory is responsible for creating threads in the thread pool. It is an object that implements the ThreadFactory interface. By customizing the thread factory, we can set personalized properties for the created threads, such as thread names, priorities, and whether they are daemon threads. This facilitates better management and identification of threads in complex project environments, as well as troubleshooting and performance tuning.
(5) Rejected Execution Handler
When the task queue of the thread pool is full and the number of threads has reached the maximum pool size, if new tasks are submitted, the thread pool needs to adopt a strategy to handle these unaccepted tasks, which is the rejection policy. Java provides several common implementations of rejection policies, such as AbortPolicy (directly throws an exception, the default rejection policy, terminating the submission of the current task), CallerRunsPolicy (the task is executed by the caller’s thread, which slows down the submission speed of new tasks and gives the thread pool buffer time to process backlogged tasks), DiscardOldestPolicy (discards the earliest task in the queue, i.e., the first task waiting in the queue, and then tries to resubmit the current new task), and DiscardPolicy (directly discards the newly submitted task without any processing). Developers can choose an appropriate rejection policy based on business needs or customize one to meet specific application scenarios.
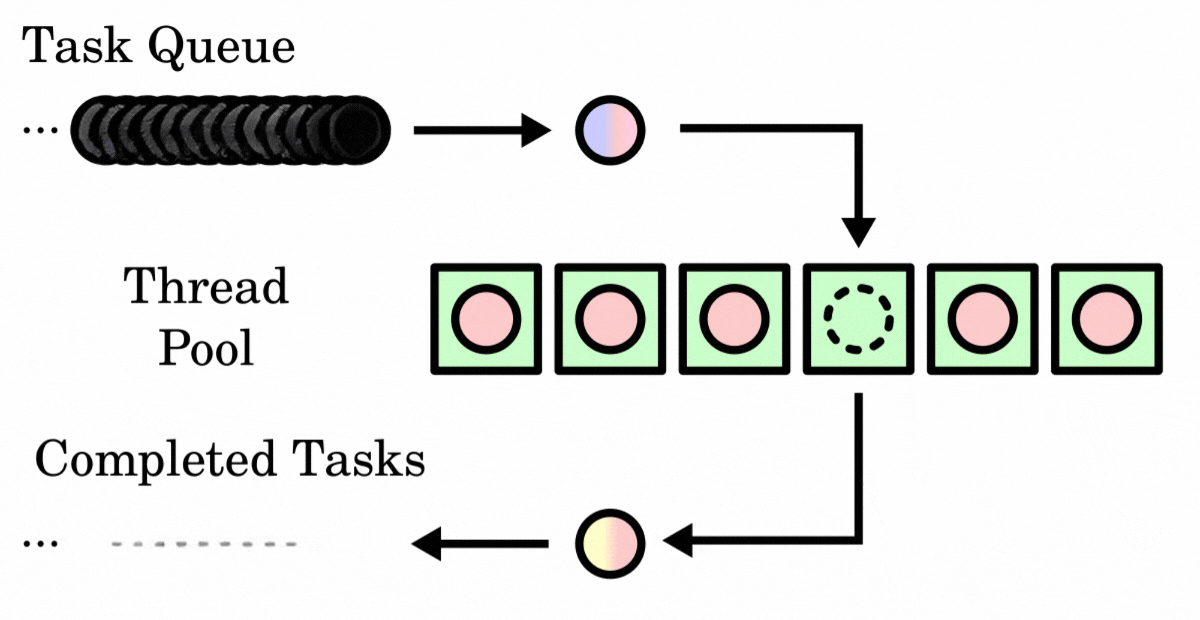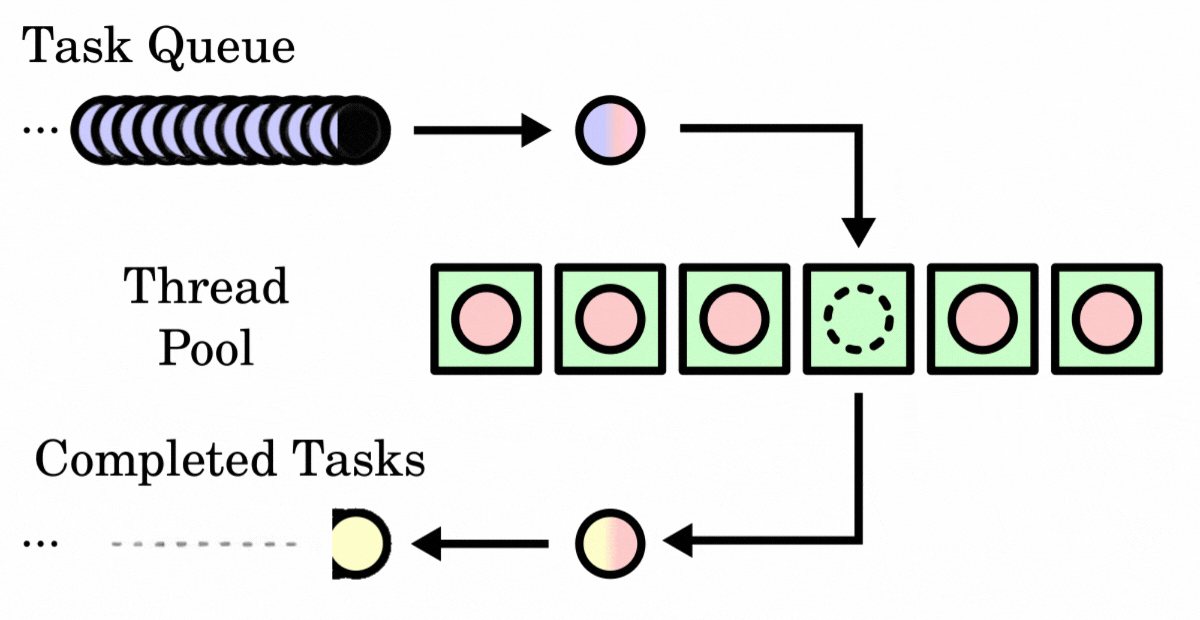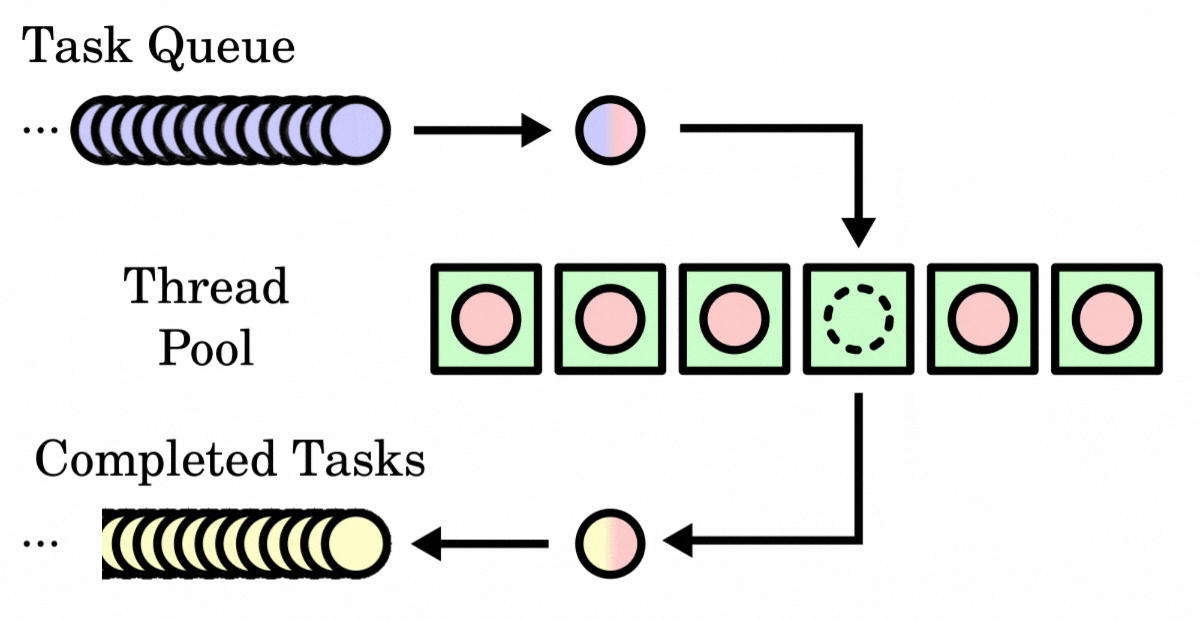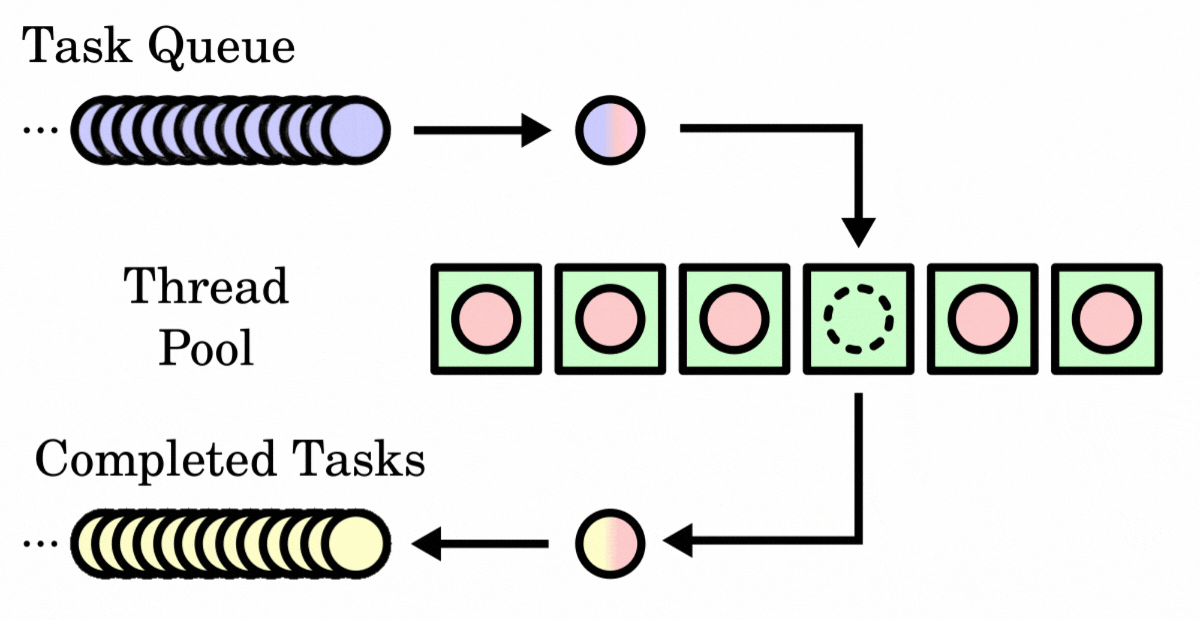
(6) Working Principle of Thread Pools
The workflow of a thread pool is roughly as follows:
- When a task is submitted to the thread pool, it first checks whether the number of running threads in the thread pool is less than the core pool size. If so, a new thread is created through the thread factory to execute the task, and the newly created thread becomes a core thread of the thread pool.
- If the number of running threads has reached the core pool size, the newly submitted task is added to the blocking queue to wait until an idle thread can fetch the task from the queue for execution.
- When the blocking queue is full and the number of running threads is less than the maximum pool size, the thread pool creates new threads to process tasks, but the total number of threads will not exceed the maximum pool size.
- If the blocking queue is full and the number of threads has reached the maximum pool size, new tasks submitted will be handled according to the set rejection policy.
3. Creation and Use of Thread Pools in Java
(1) Creating Thread Pools via the Executors Factory Class
Java provides the Executors factory class, which contains multiple static methods for conveniently creating different types of thread pools. Here are several common creation methods:
Creating a Fixed-Size Thread Pool (FixedThreadPool)
The Executors.newFixedThreadPool(int nThreads) method creates a thread pool with a fixed number of threads, where the number of threads is specified by the parameter nThreads.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolExample {
public static void main(String[] args) {
// Create a fixed-size thread pool with 5 threads
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("Executing task " + taskId + ", thread name: " + Thread.currentThread().getName());
});
}
// Shut down the thread pool, no longer accepting new tasks, waiting for submitted tasks to complete
executor.shutdown();
}
}In the above example, a fixed-size thread pool with 5 threads is created, and then 10 tasks are submitted. The thread pool uses these 5 threads to execute the tasks in a loop. The execution order of tasks depends on thread scheduling and the order in which tasks are submitted to the thread pool.
Creating a Single-Thread Thread Pool (SingleThreadExecutor)
The Executors.newSingleThreadExecutor() method creates a thread pool with only one thread. All tasks are executed in sequence by this single thread, which is suitable for scenarios requiring task execution in order, such as some scheduled task schedulers.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SingleThreadExecutorExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("Executing task " + taskId + ", thread name: " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
}In this example, no matter how many tasks are submitted, they are executed one by one in order by that single thread, ensuring that the execution order of tasks is not disrupted.
Creating a Cached Thread Pool (CachedThreadPool)
The Executors.newCachedThreadPool() method creates a thread pool that automatically creates new threads as needed. If threads are idle for more than 60 seconds, they are automatically recycled. This type of thread pool is suitable for handling a large number of short-lived tasks because it dynamically adjusts the number of threads based on the number of tasks, improving resource utilization efficiency.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CachedThreadPoolExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("Executing task " + taskId + ", thread name: " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
}In this example, depending on the task submission, the thread pool may create multiple threads to process tasks simultaneously. When threads are idle for a period, they are automatically recycled, reflecting its flexible resource allocation characteristics.
Creating a Scheduled Thread Pool (ScheduledThreadPool)
The Executors.newScheduledThreadPool(int corePoolSize) method is used to create a thread pool that can execute scheduled and periodic tasks. The parameter corePoolSize specifies the number of core threads. For example, it can be used to implement tasks that execute at a fixed time or repeat at regular intervals.
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolExample {
public static void main(String[] args) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// Execute the task after a 3-second delay
executor.schedule(() -> {
System.out.println("Task executed after a 3-second delay");
}, 3, TimeUnit.SECONDS);
// Execute the task repeatedly every 2 seconds
executor.scheduleAtFixedRate(() -> {
System.out.println("Task executed repeatedly every 2 seconds");
}, 0, 2, TimeUnit.SECONDS);
// Shut down the thread pool; note that the shutdown operation should be performed at an appropriate time to avoid affecting scheduled tasks
// executor.shutdown();
}
}In the above example, it demonstrates how to use a scheduled thread pool to implement delayed tasks and periodic tasks. By setting different time parameters, the execution schedule of tasks can be flexibly controlled.
It should be noted that although the Executors factory class provides a convenient way to create thread pools, in production environments, it is recommended to use the ThreadPoolExecutor class to manually create thread pools. This allows for more fine-grained configuration of thread pool parameters (such as core pool size, maximum pool size, and blocking queue type), avoiding potential issues caused by default configurations (e.g., CachedThreadPool may create an unlimited number of threads, exhausting system resources).
(2) Manually Creating Thread Pools via the ThreadPoolExecutor Class
ThreadPoolExecutor is the core implementation class of thread pools, providing more comprehensive and flexible thread pool configuration. Its constructor is as follows:
public ThreadPoolExecutor(int corePoolSize, // Core pool size
int maximumPoolSize, // Maximum pool size
long keepAliveTime, // Thread survival time
TimeUnit unit, // Unit of thread survival time
BlockingQueue<Runnable> workQueue, // Task queue
ThreadFactory threadFactory, // Thread factory
RejectedExecutionHandler handler) {
// Internal implementation logic of the constructor
}The meanings of each parameter correspond to the core components of the thread pool introduced earlier. By manually specifying these parameters, a thread pool that meets specific business needs can be created.
Example:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
private final AtomicInteger threadNumber = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "CustomThreadPool-" + threadNumber.getAndIncrement());
}
};
// Rejection policy, using CallerRunsPolicy here
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
for (int i = 0; i < 8; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("Executing task " + taskId + ", thread name: " + Thread.currentThread().getName());
});
}
// Shut down the thread pool
executor.shutdown();
}
}In this example, we manually created a thread pool, explicitly specifying parameters such as core pool size, maximum pool size, idle thread survival time, blocking queue type, thread factory, and rejection policy, then submitted 8 tasks to the thread pool to observe how the thread pool allocates threads to execute tasks and handles situations such as excessive tasks based on the set parameters.
First, since the core pool size is 3, 3 threads are initially created to execute the first 3 tasks. When the 4th task is submitted, as all core threads are busy, the task is added to the LinkedBlockingQueue to wait. As more tasks are submitted, the queue continues to backlog tasks. When the 6th task is submitted, if the queue is full (although LinkedBlockingQueue is theoretically unbounded, it cannot be infinitely expanded due to system resource limitations; here we assume a relative “full” state is reached) and the number of running threads is less than the maximum pool size (5), the thread pool creates 2 more new threads to execute tasks, increasing the number of threads to the maximum pool size. If more tasks are submitted subsequently, the CallerRunsPolicy rejection policy is applied, where the caller thread that submits the task executes some tasks, thereby relieving the pressure on the thread pool and ensuring tasks are processed as much as possible.
The advantage of manually creating a thread pool is that developers can finely adjust each parameter based on specific business scenarios and system resource conditions. For example, if the number of tasks is relatively stable most of the time and the approximate number of core tasks is known, the core pool size can be set reasonably; the maximum pool size can be determined based on the maximum number of concurrent threads the system can tolerate; an appropriate blocking queue type can be selected based on the average waiting time of tasks and expected resource usage; a thread factory can be customized according to thread management needs; and a rejection policy can be chosen based on the business’s tolerance for task loss. This creates a thread pool that best fits actual needs, avoids potential risks caused by default configurations, and improves the performance and stability of the system in concurrent environments.
4. Application of Thread Pools in Projects
(1) Application in Web Servers
In Web servers such as Tomcat and Jetty, thread pools are crucial for ensuring efficient server operation.
When a large number of clients initiate HTTP requests simultaneously, the server retrieves threads from a pre-configured thread pool to process the requests. Each thread is responsible for handling the business logic of a single request, such as parsing request parameters, calling service-layer methods, and generating response data. The entire process is similar to a factory assembly line, where threads process numerous client requests in parallel.
Reasonable configuration of thread pool parameters (setting core and maximum pool sizes based on server hardware resources and estimated concurrent requests) enables the server to respond quickly to requests under high concurrency while avoiding resource exhaustion due to excessive threads, ensuring stable operation and good performance of the server.
For example, in a Spring Boot-based Web application, thread pool parameters can be configured via configuration files or code to handle business such as RESTful API requests. Here is a simple example of configuring a thread pool in Spring Boot (using ThreadPoolTaskExecutor, a Spring encapsulation of ThreadPoolExecutor for easy use in Spring frameworks):
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
public class ThreadPoolConfig {
@Bean
public Executor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(20);
executor.setQueueCapacity(50);
executor.setThreadNamePrefix("WebServerThreadPool-");
executor.initialize();
return executor;
}
}In the above configuration, the core pool size is set to 10, meaning 10 threads are always ready to process requests under normal circumstances; the maximum pool size is 20, so when concurrent requests increase and core threads are insufficient, the number of threads can be expanded to 20 to process tasks; the queue capacity is 50, used to store request tasks that cannot be processed immediately, allowing them to wait for idle threads. Setting a thread name prefix facilitates quick identification of the thread pool and purpose of threads during logging and debugging.
In business code, methods can be marked for asynchronous execution using the @Async annotation, and these asynchronous tasks are processed by the configured thread pool. An example is as follows:
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Async("asyncExecutor")
public void processUserData() {
// Write business logic for processing user data here, such as reading user data from the database and processing it
// Since it is marked for asynchronous execution, this method will be executed by threads in the configured thread pool
}
}In this way, thread pools are efficiently used in Web servers to handle various concurrent businesses, improving the response speed and concurrent processing capability of the entire application. For example, in an e-commerce website, when multiple users place orders, query product information, or browse different pages simultaneously, the server allocates threads through the thread pool to respond to these requests quickly, ensuring a smooth shopping experience for users and avoiding long page loading or lag caused by slow request processing.
(2) Application in Big Data Processing Scenarios
In the field of big data processing, such as analyzing, cleaning, and aggregating massive amounts of data, it is often necessary to process multiple data blocks in parallel or execute multiple related computing tasks. Thread pools play an indispensable role here, acting as an efficient “data processing factory” that coordinates multiple threads to complete complex data processing tasks together.
For example, in a big data project based on the Hadoop ecosystem, when executing a MapReduce task, the Map phase can divide input data into multiple blocks, and then the thread pool allocates multiple threads to process different data blocks simultaneously (such as parsing data and extracting key information). Each thread is like a diligent “data craftsman” focusing on processing its assigned data block, which fully utilizes the computing power of multi-core CPUs and significantly accelerates data processing. The Reduce phase can also use thread pools to process data aggregation and calculation for each partition in parallel, integrating and aggregating data processed in the Map phase to generate the desired result data.
By reasonably setting thread pool parameters, combined with data volume and cluster hardware resources, the speed of the entire big data processing process can be optimized and processing time reduced. For example, the core pool size and maximum pool size of the thread pool can be determined based on the number of CPU cores and memory size of nodes in the cluster, and an appropriate blocking queue can be selected to store pending data tasks, ensuring efficient data flow between threads and avoiding data backlogs or threads idling while waiting for tasks.
Another example is in distributed computing using Spark, where Spark extensively uses thread pool mechanisms to manage threads for executing various computing tasks, processing data partitions, and transmitting data between different nodes. This ensures that computing of massive data in large-scale cluster environments can be performed efficiently and stably. Spark dynamically adjusts thread pool parameters based on task complexity, data distribution, and cluster resource conditions, automatically allocating threads to process different partitioned data, enabling fast parallel computing of data. This allows big data analysis operations to be completed in a short time, providing strong support for enterprises to quickly obtain valuable data insights.
(3) Application in Enterprise-Level Backend Services
In enterprise-level backend services, thread pools are one of the core mechanisms ensuring stable and efficient system operation.
Many enterprise-level applications need to process massive business data and handle a large number of external requests. For example, banking systems need to process various account transactions, fund transfers, and account queries; logistics management systems must handle cargo warehousing, outbound, transportation scheduling, and logistics information queries simultaneously; customer relationship management (CRM) systems involve customer information entry, updates, queries, and sales lead follow-ups, among many other business processes.
Taking banking systems as an example, a large number of customers initiate transaction requests through online banking, mobile banking, and offline counters every day. The timeliness and accuracy of processing these requests are crucial. By setting reasonable thread pools, different types of transaction requests can be assigned to different threads or thread groups for processing. For example, fund transfer tasks can be assigned to a thread pool with specific configurations, and account query tasks to another thread pool focused on response speed. Thread pool parameters can be dynamically adjusted according to peak and off-peak business hours: expanding the number of threads during busy hours to cope with high concurrency, and reducing thread resource usage during idle hours, ensuring the system can always process various transactions efficiently and stably, maintaining the normal operation of financial services.
In logistics management systems, cargo warehousing and outbound operations may involve collaborative processes such as reading and writing inventory databases and controlling warehousing equipment. Allocating threads through thread pools to process operations related to different cargos in parallel can accelerate overall logistics processing efficiency and reduce the time cargo stays in the warehouse. Transportation scheduling tasks involve complex route planning and vehicle allocation calculations; multiple threads participating in calculations through the thread pool can quickly determine the optimal transportation plan, improving the utilization of logistics resources and ensuring cargo is delivered on time and accurately.
The same applies to CRM systems. When many salespersons update customer information and query sales leads simultaneously, thread pools ensure parallel processing of these tasks, avoiding slow system response or data conflicts caused by a large number of concurrent operations, improving the efficiency and quality of enterprise customer relationship management, and helping enterprises better serve customers and enhance market competitiveness.